Chapter 5. Text API Overview
The next few chapters look at programming with the text document part of the Office API. This chapter begins with a quick overview of the text API, then a detailed look at text cursors for moving about in a document, extracting text, and adding/inserting new text.
Text cursors aren’t the only way to move around inside a document; it’s also possible to iterate over a document by treating it as a sequence of paragraphs.
The chapter finishes with a look at how two (or more) text documents can be appended.
The online Developer’s Guide begins text document programming at
https://wiki.openoffice.org/wiki/Documentation/DevGuide/Text/Text_Documents (the easiest way of accessing that page is to type loguide writer).
It corresponds to Chapter 7 in the printed guide (available at https://wiki.openoffice.org/w/images/d/d9/DevelopersGuide_OOo3.1.0.pdf),
but the Web material is better structured and formatted.
The guide’s text programming examples are in TextDocuments.java.
Although the code is long, it’s well-organized. Some smaller text processing examples are available at https://api.libreoffice.org/examples/examples.html#Java_examples.
This chapter (and later ones) assume that you’re familiar with Writer, including text concepts such as paragraph styles. If you’re not, then I recommend the Writer Guide, user manual.
5.1 An Overview of the Text Document API
The API is centered around four text document services which sub-class OfficeDocument, as shown in Fig. 25.
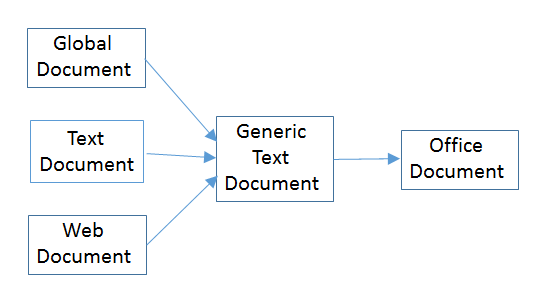
Fig. 25 :The Text Document Services.
This chapter concentrates on the TextDocument service.
Or you can type lodoc TextDocument service.
The GlobalDocument service in Fig. 25 is employed by master documents, such as a book or thesis.
A master document is typically made up of links to files holding its parts, such as chapters, bibliography, and appendices.
The WebDocument service in Fig. 25 is for manipulating web pages, although its also possible to generate HTML files with the TextDocument service.
TextDocument, GlobalDocument, and WebDocument are mostly empty because those services don’t define any interfaces or properties.
The GenericTextDocument service is where the action takes place, as summarized in Fig. 26.
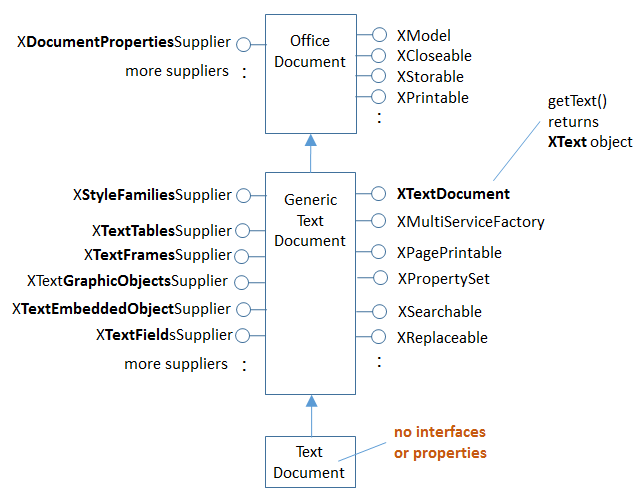
Fig. 26 :The Text Document Services, and some Interfaces.
The numerous ‘Supplier’ interfaces in Fig. 26 are Office’s way of accessing different elements in a document.
For example, XStyleFamiliesSupplier manages character, paragraph, and other styles, while XTextTableSupplier deals with tables.
In later chapters we will be looking at these suppliers, which is why they’re highlighted,
but for now let’s only consider the XTextDocument interface at the top right of the GenericTextDocument service box
in Fig. 26 XTextDocument has a getText() method for returning an XText object.
XText supports functionality related to text ranges and positions, cursors, and text contents.
It inherits XSimpleText and XTextRange, as indicated in Fig. 27.
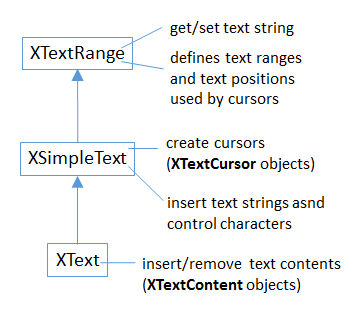
Fig. 27 : XText and its Super-classes.
Text content covers a multitude, such as embedded images, tables, footnotes, and text fields.
Many of the suppliers shown in Fig. 26 (ex: XTextTablesSupplier)
are for iterating through text content (ex: accessing the document’s tables).
This chapter concentrates on ordinary text, Chapter 7. Text Content Other than Strings and Chapter 8. Graphic Content look at more esoteric content forms.
A text document can utilize eight different cursors, which fall into two groups, as in Fig. 28.
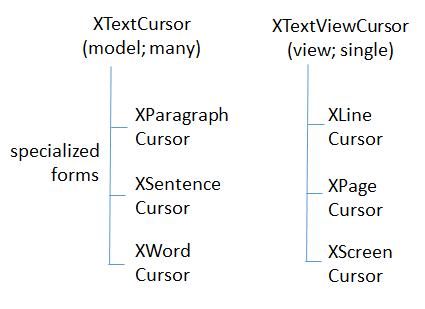
Fig. 28 :Types of Cursor.
XTextCursor contains methods for moving around the document, and an instance is often called a model cursor
because of its close links to the document’s data. A program can create multiple XTextCursor objects if it wants,
and can convert an XTextCursor into XParagraphCursor, XSentenceCursor, or XWordCursor.
The differences are that while an XTextCursor moves through a document character by character, the others travel in units of paragraphs, sentences, and words.
A program may employ a single XTextViewCursor cursor, to represent the cursor the user sees in the Writer application window;
for this reason, it’s often called the view cursor. XTextViewCursor can be converted into a XLineCursor, XPageCursor, or XScreenCursor object,
which allows it to move in terms of lines, pages, or screens.
A cursor’s location is specified using a text range, which can be the currently selected text, or a position in the document. A text position is a text range that begins and ends at the same point.
5.2 Extracting Text from a Document
The Extract Writer Text example opens a document using Lo.open_doc(), and tries to print its text:
#!/usr/bin/env python
# coding: utf-8
from __future__ import annotations
import argparse
from typing import cast
from ooodev.office.write import Write
from ooodev.utils.info import Info
from ooodev.loader.lo import Lo
from ooodev.wrapper.break_context import BreakContext
def args_add(parser: argparse.ArgumentParser) -> None:
parser.add_argument(
"-f",
"--file",
help="File path of input file to convert",
action="store",
dest="file_path",
required=True,
)
def main() -> int:
parser = argparse.ArgumentParser(description="main")
args_add(parser=parser)
args = parser.parse_args()
with BreakContext(Lo.Loader(connector=Lo.ConnectSocket(headless=True))) as loader:
fnm = cast(str, args.file_path)
try:
doc = Lo.open_doc(fnm=fnm, loader=loader)
except Exception:
print(f"Could not open '{fnm}'")
raise BreakContext.Break
if Info.is_doc_type(obj=doc, doc_type=Lo.Service.WRITER):
text_doc = Write.get_text_doc(doc=doc)
cursor = Write.get_cursor(text_doc)
text = Write.get_all_text(cursor)
print("Text Content".center(50, "-"))
print(text)
print("-" * 50)
else:
print("Extraction unsupported for this doc type")
Lo.close_doc(doc)
return 0
if __name__ == "__main__":
raise SystemExit(main())
Info.is_doc_type() tests the document’s type by casting it into an XServiceInfo interface. Then it calls XServiceInfo.supportsService()
to check the document’s service capabilities:
@staticmethod
def is_doc_type(obj: object, doc_type: Lo.Service) -> bool:
try:
si = Lo.qi(XServiceInfo, obj)
if si is None:
return False
return si.supportsService(str(doc_type))
except Exception:
return False
The argument type of the document is Object rather than XComponent so that a wider range of objects can be passed to the function for testing.
The service names for documents are hard to remember, so they’re defined as an enumeration in the Lo.Service.
Write.get_text_doc() uses Lo.qi() to cast the document’s XComponent interface into an XTextDocument:
text_doc = Lo.qi(XTextDocument, doc, True)
text_doc = Lo.qi(XTextDocument, doc) This may fail (i.e. return None) if the loaded document isn’t an instance of the TextDocument service.
The casting ‘power’ of Lo.qi() is confusing – it depends on the document’s service type.
All text documents are instances of the TextDocument service (see Fig. 26).
This means that Lo.qi() can ‘switch’ between any of the interfaces defined by TextDocument
or its super-classes (i.e. the interfaces in GenericTextDocument or OfficeDocument).
For instance, the following cast is fine:
xsupplier = Lo.qi(XStyleFamiliesSupplier, doc)
This changes the instance into an XStyleFamiliesSupplier, which can access the document’s styles.
Alternatively, the following converts the instance into a supplier defined in OfficeDocument:
xsupplier = Lo.qi(XDocumentPropertiesSupplier, doc)
Most of the examples in this chapter and the next few cast the document to XTextDocument since that interface can access the document’s contents as an XText object:
text_doc = Lo.qi(XTextDocument, doc)
xtext = text_doc.getText()
The XText instance can access all the capabilities shown in Fig. 27.
A common next step is to create a cursor for moving around the document.
This is easy since XText inherits XSimpleText which has a createTextCursor() method:
text_cursor = xText.createTextCursor()
These few lines are so useful that they are part of Selection.get_cursor() method which Write inherits.
An XTextCursor can be converted into other kinds of model cursors (eg:
XParagraphCursor, XSentenceCursor, XWordCursor; see Fig. 28).
That’s not necessary in for the Extract Writer Text example; instead, the XTextCursor is passed to
Write.get_all_text() to access the text as a sequence of characters:
@staticmethod
def get_all_text(cursor: XTextCursor) -> str:
cursor.gotoStart(False)
cursor.gotoEnd(True)
text = cursor.getString()
cursor.gotoEnd(False) # to deselect everything
return text
All cursor movement operations take a boolean argument which specifies whether the movement should also select the text.
For example, in get_all_text(), cursor.gotoStart(False) shifts the cursor to the start of the text without selecting anything.
The subsequent call to cursor.gotoEnd(True) moves the cursor to the end of the text and selects all the text moved over.
The call to getString() on the third line returns the selection (eg: all the text in the document).
Two other useful XTextCursor methods are:
cursor.goLeft(char_count, is_selected)
cursor.goRight(char_count, is_selected)
They move the cursor left or right by a given number of characters, and the boolean argument specifies whether the text moved over is selected.
All cursor methods return a boolean result which indicates if the move (and optional selection) was successful.
Another method worth knowing is:
cursor.gotoRange(text_range, is_selected)
gotoRange() method of XTextCursor takes an XTextRange argument, which represents a selected region or position where the cursor should be moved to.
For example, it’s possible to find a bookmark in a document, extract its text range/position, and move the cursor to that location with gotoRange().
Code for this in Chapter 7. Text Content Other than Strings.
A Problem with Write.get_all_text()
get_all_text() may fail if supplied with a very large document because XTextCursor.getString() might be unable to construct a big enough String object.
For that reason, it’s better to iterate over large documents returning a paragraph of text at a time.
These iteration techniques are described next.
5.3 Cursor Iteration
Since 0.16.0, OooDev provides a new way of work with documents. This is done via the ooodev.write module and sub-modules.
Previously accessing text cursors meant getting access to various cursor interface such as XParagraphCursor and XWordCursor as seen in Fig. 28
In the Walk Text example it uses paragraph, word and view cursors via Class WriteTextCursor and Class WriteTextViewCursor classes.
def main() -> int:
parser = argparse.ArgumentParser(description="main")
args_add(parser=parser)
if len(sys.argv) == 1:
pth = Path(__file__).parent / "data" / "cicero_dummy.odt"
sys.argv.append("-f")
sys.argv.append(str(pth))
args = parser.parse_args()
loader = Lo.load_office(Lo.ConnectSocket())
fnm = cast(str, args.file_path)
try:
doc = WriteDoc(Write.open_doc(fnm=fnm, loader=loader))
doc.set_visible()
show_paragraphs(doc)
print(f"Word count: {count_words(doc)}")
show_lines(doc)
Lo.delay(1_000)
msg_result = MsgBox.msgbox(
"Do you wish to close document?",
"All done",
boxtype=MessageBoxType.QUERYBOX,
buttons=MessageBoxButtonsEnum.BUTTONS_YES_NO,
)
if msg_result == MessageBoxResultsEnum.YES:
doc.close_doc()
Lo.close_office()
else:
print("Keeping document open")
except Exception as e:
print(e)
Lo.close_office()
raise
return 0
main() calls Write.open_doc() to return the opened document as an XTextDocument instance.
If you recall, the previous Extract Writer Text example started with an XComponent instance by calling
Lo.open_doc(), and then converted it to XTextDocument. Write.open_doc() returns the XTextDocument reference in one go.
Class WriteText is a wrapper around the XTextDocument instance, and provides a many convenience methods for accessing the document’s text and cursors:
show_paragraphs() moves the visible on-screen cursor through the document, highlighting a paragraph at a time.
This requires two cursors – an instance of XTextViewCursor and a separate XParagraphCursor which are accessed by calling Write.get_view_cursor().
The paragraph cursor is capable of moving through the document paragraph-by-paragraph, but it’s a model cursor, so invisible to the user
looking at the document on-screen. show_paragraphs() extracts the start and end positions of each paragraph and uses them to move the view cursor, which is visible.
The code for show_paragraphs():
def show_paragraphs(doc: WriteDoc) -> None:
tvc = doc.get_view_cursor()
cursor = doc.get_cursor()
cursor.goto_start(False) # go to start test; no selection
while 1:
cursor.goto_end_of_paragraph(True) # select all of paragraph
curr_para = cursor.get_string()
if len(curr_para) > 0:
tvc.goto_range(cursor.component.getStart())
tvc.goto_range(cursor.component.getEnd(), True)
print(f"P<{curr_para}>")
Lo.delay(500) # delay half a second
if cursor.goto_next_paragraph() is False:
break
The code utilizes two Write utility functions (WriteDoc.get_view_cursor() and WriteDoc.get_cursor()) to create the cursors.
The subsequent while loop is a common coding pattern for iterating over a text document:
cursor.goto_start(False) # go to start test; no selection
while 1:
cursor.goto_end_of_paragraph(True) # select all of paragraph
curr_para = cursor.get_string()
# do something with selected text range.
if cursor.goto_next_paragraph() is False:
break
goto_next_paragraph() tries to move the cursor to the beginning of the next paragraph.
If the moves fails (i.e. when the cursor has reached the end of the document), the function returns False, and the loop terminates.
The call to goto_end_of_paragraph(True) at the beginning of the loop moves the cursor to the end of the paragraph and selects its text.
Since the cursor was originally at the start of the paragraph, the selection will span that paragraph.
The cursor object above implements method for XParagraphCursor and the sentence and word cursors inherit XTextCursor, as shown in Fig. 29.
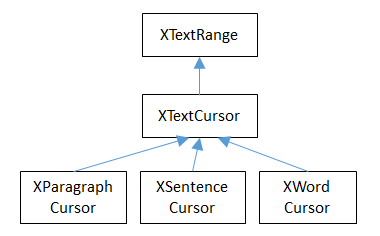
Fig. 29 :The Model Cursors Inheritance Hierarchy.
Since all these cursors also inherit XTextRange, they can easily access and change their text selections/positions.
In the show_paragraphs() method above, the two ends of the paragraph are obtained by calling the inherited
XTextRange.getStart() and XTextRange.getEnd(), and the positions are used to move the view cursor:
tvc = doc.get_view_cursor()
cursor = doc.get_cursor()
...
tvc.goto_range(cursor.component.getStart())
tvc.goto_range(cursor.component.getEnd(), True)
goto_range() sets the text range/position of the view cursor: the first call moves the cursor to the paragraph’s starting position
without selecting anything, and the second moves it to the end position, selecting all the text in between.
Since this is a view cursor, the selection is visible on-screen, as illustrated in Fig. 30.

Fig. 30 :A Selected Paragraph.
Note that getStart() and getEnd() do not return integers but collapsed text ranges,
which is Office-lingo for a range that starts and ends at the same cursor position.
Somewhat confusingly, the XTextViewCursor interface inherits XTextCursor (as shown in Fig. 31). This only means that XTextViewCursor supports the same character-based movement and text range operations as the model-based cursor.
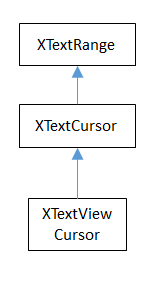
Fig. 31 :The XTextViewCursor Inheritance Hierarchy.
5.4 Creating Cursors
An XTextCursor is created by calling Write.get_cursor(), which can then be converted into a paragraph, sentence, or word cursor by using
Lo.qi(). For example, the Selection utility class defines get_paragraph_cursor() as:
@classmethod
def get_paragraph_cursor(cls, cursor_obj: DocOrCursor) -> XParagraphCursor:
try:
if Lo.qi(XTextDocument, cursor_obj) is None:
cursor = cursor_obj
else:
cursor = cls.get_cursor(cursor_obj)
para_cursor = Lo.qi(XParagraphCursor, cursor, True)
return para_cursor
except Exception as e:
raise ParagraphCursorError(str(e)) from e
Obtaining the view cursor is a little more tricky since it’s only accessible via the document’s controller.
As described in 1.5 The FCM Relationship, the controller is reached via the document’s model, as shown in the first three lines of
Selection.get_view_cursor():
@staticmethod
def get_view_cursor(text_doc: XTextDocument) -> XTextViewCursor:
try:
model = Lo.qi(XModel, text_doc, True)
xcontroller = model.getCurrentController()
supplier = Lo.qi(XTextViewCursorSupplier, xcontroller, True)
vc = supplier.getViewCursor()
if vc is None:
raise Exception("Supplier return null view cursor")
return vc
except Exception as e:
raise ViewCursorError(str(e)) from e
The view cursor isn’t directly accessible from the controller; a supplier must be queried, even though there’s only one view cursor per document.
5.4.1 Counting Words
count_words() in Walk Text shows how to iterate over the document using a word cursor:
def count_words(doc: WriteDoc) -> int:
cursor = doc.get_cursor()
cursor.goto_start() # go to start of text
word_count = 0
while 1:
cursor.goto_end_of_word(True)
curr_word = cursor.get_string()
if len(curr_word) > 0:
word_count += 1
if cursor.goto_next_word() is False:
break
return word_count
This uses the same kind of while loop as show_paragraphs() except that the methods
goto_end_of_word() and goto_next_word() control the iteration.
Also, there’s no need for an XTextViewCursor instance since the selected words aren’t shown on the screen.
5.4.2 Displaying Lines
show_lines() in Walk Text iterates over the document highlighting a line at a time.
Don’t confuse this with sentence selection because a sentence may consist of several lines on the screen.
A sentence is part of the text’s organization (eg: in terms of words, sentences, and paragraphs)
while a line is part of the document view (eg: line, page, screen).
This means that XLineCursor is a view cursor, which is obtained by converting XTextViewCursor with Lo.qi().
Class WriteTextViewCursor hides the need for this conversion by including the method for XLineCursor:
tvc = Write.get_view_cursor(doc)
line_cursor = Lo.qi(XLineCursor, tvc, True)
The line cursor has limited functionality compared to the model cursors (paragraph, sentence, word).
In particular, there’s no “next’ function for moving to the next line (unlike goto_next_paragraph() or goto_next_word()).
The screen cursor also lacks this ability, but the page cursor offers jump_to_next_page().
One way of getting around the absence of a ‘next’ operation is shown in show_lines():
def show_lines(doc: WriteDoc) -> None:
tvc = doc.get_view_cursor()
tvc.goto_start() # go to start of text
have_text = True
while have_text is True:
tvc.goto_start_of_line()
tvc.goto_end_of_line(True)
print(f"L<{tvc.get_string()}>") # no text selection in line cursor
Lo.delay(500) # delay half a second
tvc.collapse_to_end()
have_text = tvc.go_right(1, True)
The view cursor is manipulated using the XTextViewCursor object and the XLineCursor line cursor. This is possible since the two references point to the same on-screen cursor. Either one can move it around the display.
Inside the loop, Class WriteTextViewCursor goto_start_of_line() and goto_end_of_line() highlight a single line.
Then the XTextViewCursor instance is invoked and deselects the line, by moving the cursor to the end of the selection with collapse_to_end().
At the end of the loop, go_right() tries to move the cursor one character to the right.
If go_right() succeeds then the cursor is shifted one position to the first character of the next line. When the loop repeats, this line will be selected.
If go_right() fails, then there are no more characters to be read from the document, and the loop finishes.
5.5 Creating a Document
All the examples so far have involved the manipulation of an existing document. The Hello Save example creates a new text document, containing two short paragraphs, and saves it as “hello.odt”. The main() function is:
def main() -> int:
with Lo.Loader(Lo.ConnectSocket()) as loader:
doc = WriteDoc(Write.create_doc(loader))
doc.set_visible()
Lo.delay(300) # small delay before dispatching zoom command
doc.zoom(ZoomKind.PAGE_WIDTH)
cursor = doc.get_cursor()
cursor.goto_end() # make sure at end of doc before appending
cursor.append_para(text="Hello LibreOffice.\n")
Lo.delay(1_000) # Slow things down so user can see
cursor.append_para(text="How are you?")
Lo.delay(2_000)
tmp = Path.cwd() / "tmp"
tmp.mkdir(exist_ok=True, parents=True)
doc.save_doc(fnm=tmp / "hello.odt")
doc.close_doc()
return 0
Write.create_doc() calls Lo.create_doc() with the text document service name (the Lo.DocTypeStr.WRITER enum value is swriter).
Office creates a TextDocument service with an XComponent interface, which is cast to the XTextDocument interface, and returned:
The XTextDocument instance is passed to WriteDoc which is a wrapper around the document, and provides many convenience methods for accessing the document’s text and cursors:
# simplified version of Write.create_doc
@staticmethod
def create_doc(loader: XComponentLoader) -> XTextDocument:
doc = Lo.qi(
XTextDocument,
Lo.create_doc(doc_type=Lo.DocTypeStr.WRITER, loader=loader),
True,
)
return doc
Text documents are saved using WriteDoc.save_doc() that calls Lo.save_doc() which was described in 2.5 Saving a Document.
save_doc() examines the filename’s extension to determine its type.
The known extensions include doc, docx, rtf, odt, pdf, and txt.
Back in Hello Save, a cursor is needed before text can be added; one is created by calling doc.get_cursor().
The call to cursor.goto_end() isn’t really necessary because the new cursor is pointing to an empty document so is already at its end.
It’s included to emphasize the assumption by cursor.append_para() (and other cursor.appendXXX() functions) that the cursor is
positioned at the end of the document before new text is added.
cursor.append_para() calls Write.append() methods:
# simplified version of Write.append_para
@classmethod
def append_para(cls, cursor: XTextCursor, text: str) -> None:
cls.append(cursor=cursor, text=text)
cls.append(cursor=cursor, ctl_char=Write.ControlCharacter.PARAGRAPH_BREAK)
The append() name is utilized several times in Write via it overloads:
append(cursor: XTextCursor, text: str)
append(cursor: XTextCursor, ctl_char: ControlCharacter)
append(cursor: XTextCursor, text_content: com.sun.star.text.XTextContent)
append(cursor: XTextCursor, text: str) appends text using XTextCursor.setString() to add the user-supplied string.
append(cursor: XTextCursor, ctl_char: ControlCharacter) uses XTextCursor.insertControlCharacter().
After the addition of the text or character, the cursor is moved to the end of the document.
append(cursor: XTextCursor, text_content: com.sun.star.text.XTextContent) appends an object
that is a sub-class of XTextContent
ControlCharacter is an enumeration of API ControlCharacter.
Thanks to ooouno library that among other things automatically creates enums for LibreOffice Constants.
Write.ControlCharacter is an alias for convenience.
The various cursor of the ooodev.write module also have appendXXX() methods but the methods to no require a XTextCursor argument.
from ooo.dyn.text.control_character import ControlCharacterEnum
class Write(Selection):
ControlCharacter = ControlCharacterEnum
Selection.get_position() (inherited by Write) gets the current position if the cursor from the start of the document.
This method is not full optimized and may not be robust on large files.
Office deals with this size issue by using XTextRange instances, which encapsulate text ranges and
positions. Selection.get_position() returns an integer because its easier to understand when you’re first learning to program with Office.
It’s better style to use and compare XTextRange objects rather than integer positions, an approach demonstrated in the next section.
5.6 Using and Comparing Text Cursors
Speak Text example utilizes the third-party library text-to-speech to convert text into speech.
The inner workings aren’t relevant here, so are hidden inside a single method speak().
Speak Text employs two text cursors: a paragraph cursor that iterates over the paragraphs in the document,
and a sentence cursor that iterates over all the sentences in the current paragraph and passes each sentence to speak().
text-to-speech is capable of speaking long or short sequences of text, but Speak Text processes a sentence at a time since this sounds more natural when spoken.
The crucial function in Speak Text is speak_sentences():
def speak_sentences(doc: XTextDocument) -> None:
tvc = Write.get_view_cursor(doc)
para_cursor = Write.get_paragraph_cursor(doc)
para_cursor.gotoStart(False) # go to start test; no selection
while 1:
para_cursor.gotoEndOfParagraph(True) # select all of paragraph
end_para = para_cursor.getEnd()
curr_para_str = para_cursor.getString()
print(f"P<{curr_para_str}>")
if len(curr_para_str) > 0:
# set sentence cursor pointing to start of this paragraph
cursor = para_cursor.getText().createTextCursorByRange(para_cursor.getStart())
sc = Lo.qi(XSentenceCursor, cursor)
sc.gotoStartOfSentence(False)
while 1:
sc.gotoEndOfSentence(True) # select all of sentence
# move the text view cursor to highlight the current sentence
tvc.gotoRange(sc.getStart(), False)
tvc.gotoRange(sc.getEnd(), True)
curr_sent_str = strip_non_word_chars(sc.getString())
print(f"S<{curr_sent_str}>")
if len(curr_sent_str) > 0:
speak(
curr_sent_str,
)
if Write.compare_cursor_ends(sc.getEnd(), end_para) >= Write.CompareEnum.EQUAL:
print("Sentence cursor passed end of current paragraph")
break
if sc.gotoNextSentence(False) is False:
print("# No next sentence")
break
if para_cursor.gotoNextParagraph(False) is False:
break
speak_sentences() comprises two nested loops: the outer loop iterates through the paragraphs, and the inner loop through the sentences in the current paragraph.
The sentence cursor is created like so:
cursor = para_cursor.getText().createTextCursorByRange(para_cursor.getStart())
sc = Lo.qi(XSentenceCursor, cursor)
The XText reference is returned by para_cursor.getText(), and a text cursor is created.
createTextCursorByRange() allows the start position of the cursor to be specified. The text cursor is converted into a sentence cursor with Lo.qi().
The tricky aspect of this code is the meaning of para_cursor.getText() which is the XText object that para_cursor utilizes.
This is not a single paragraph but the entire text document.
Remember that the paragraph cursor is created with: para_cursor = Write.get_paragraph_cursor(doc) This corresponds to:
xtext = doc.getText()text_cursor = xtext.createTextCursor()para_cursor = Lo.qi(XParagraphCursor, text_cursor)Both the paragraph and sentence cursors refer to the entire text document. This means that it is not possible to code the inner loop using the coding pattern from before.That would result in something like the following:
# set sentence cursor to point to start of this paragraph
cursor = para_cursor.getText().createTextCursorByRange(para_cursor.getStart())
sc = Lo.qi(XSentenceCursor, cursor)
sc.gotoStartOfSentence(False) # goto start
while 1:
sc.gotoEndOfSentence(True) #select 1 sentence
if sc.gotoNextSentence(False) is False:
break
Note
To further confuse matters, a XText object does not always correspond to the entire text document.
For example, a text frame (e.g. like this one) can return an XText object for the text only inside the frame.
The problem with the above code fragment is that XSentenceCursor.gotoNextSentence() will keep moving to the next sentence until it reaches the end of the text document.
This is not the desired behavior – what is needed for the loop to terminate when the last sentence of the current paragraph has been processed.
We need to compare text ranges, in this case the end of the current sentence with the end of the current paragraph.
This capability is handled by the XTextRangeCompare interface. A comparer object is created at the beginning of speak_sentence(),
initialized to compare ranges that can span the entire document:
if Write.compare_cursor_ends(sc.getEnd(), end_para) >= Write.CompareEnum.EQUAL:
print("Sentence cursor passed end of current paragraph")
break
Selection.compare_cursor_ends() compares cursors ends and returns an enum value.
If the sentence ends after the end of the paragraph then compare_cursor_ends() returns a value greater or equal to Write.CompareEnum.EQUAL, and the inner loop terminates.
Since there’s no string being created by the comparer, there’s no way that the instantiating can fail due to the size of the text.
5.7 Inserting/Changing Text in a Document
The Shuffle Words example searches a document and changes the words it encounters. Fig. 32 shows the program output. Words longer than three characters are scrambled.

Fig. 32 :Shuffling of Words.
A word shuffle is applied to every word of four letters or more, but only involves the random exchange of the middle letters without changing the first and last characters.
The apply_shuffle() function which iterates through the words in the input file is similar to count_words() in Walk Text.
One difference is the use of XText.insertString() by calling doc_text.insert_string():
def apply_shuffle(doc: WriteDoc, delay: int, visible: bool) -> None:
doc_text = doc.get_text()
if visible:
cursor = doc.get_view_cursor()
else:
cursor = doc.get_cursor()
word_cursor = doc.get_cursor()
word_cursor.goto_start() # go to start of text
while True:
word_cursor.goto_next_word(True)
# move the text view cursor, and highlight the current word
cursor.goto_range(word_cursor.component.getStart())
cursor.goto_range(word_cursor.component.getEnd(), True)
curr_word = word_cursor.get_string()
# get whitespace padding amounts
c_len = len(curr_word)
curr_word = curr_word.lstrip()
l_pad = c_len - len(curr_word) # left whitespace padding amount
curr_word = curr_word.rstrip()
r_pad = c_len - len(curr_word) - l_pad # right whitespace padding amount
if len(curr_word) > 0:
pad_l = " " * l_pad # recreate left padding
pad_r = " " * r_pad # recreate right padding
Lo.delay(delay)
mid_shuffle = do_mid_shuffle(curr_word)
doc_text.insert_string(
word_cursor.component, f"{pad_l}{mid_shuffle}{pad_r}", True
)
if word_cursor.goto_next_word() is False:
break
word_cursor.goto_start() # go to start of text
cursor.goto_start()
insertString() is located in XSimpleText and is invoked when doc_text.insert_string() is called.
def insertString(xRange: XTextRange, aString: str, bAbsorb: bool) -> None:
void insertString(XTextRange xRange, String aString, boolean bAbsorb)
The string s is inserted at the cursor’s text range position.
If bAbsorb is true then the string replaces the current selection (which is the case in apply_shuffle()).
mid_shuffle() shuffles the string in curr_word, returning a new word. It doesn’t use the Office API, so no explanation here.
5.8 Treating a Document as Paragraphs and Text Portions
Another approach for moving around a document involves the XEnumerationAccess interface which treats the document as a series of Paragraph text contents.
XEnumerationAccess is an interface in the Text service, which means that an XText reference can be converted into it by using Lo.qi().
These relationships are shown in Fig. 33.

Fig. 33 :The Text Service and its Interfaces.
The following code fragment utilizes this technique:
xtext = doc.getText()
enum_access = Lo.qi(XEnumerationAccess, xtext);
XEnumerationAccess contains a single method, createEnumeration() which creates an enumerator (an instance of XEnumeration).
Each element returned from this iterator is a Paragraph text content:
# create enumerator over the document text
enum_access = Lo.qi(XEnumerationAccess, doc.getText())
text_enum = enum_access.createEnumeration()
while text_enum.hasMoreElements():
text_con = Lo.qi(XTextContent, text_enum.nextElement())
# use the Paragraph text content (text_con) in some way...
Paragraph doesn’t support its own interface (i.e. there’s no XParagraph), so Lo.qi() is used to access its XTextContent interface,
which belongs to the TextContent subclass. The hierarchy is shown in Fig. 34.
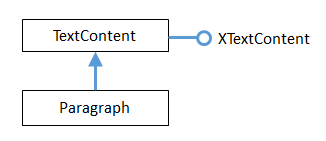
Fig. 34 :The Paragraph Text Content Hierarchy.
Iterating over a document to access Paragraph text contents doesn’t seem much different from iterating over a document using a paragraph cursor, except that the Paragraph service offers a more structured view of a paragraph.
In particular, you can use another XEnumerationAccess instance to iterate over a single paragraph, viewing it as a sequence of text portions.
The following code illustrates the notion, using the text_con text content from the previous piece of code:
if not Info.support_service(text_con, "com.sun.star.text.TextTable"):
para_enum = Write.get_enumeration(text_con)
while para_enum.hasMoreElements():
txt_range = Lo.qi(XTextRange, para_enum.nextElement())
# use the text portion (txt_range) in some way...
The TextTable service is a subclass of Paragraph, and cannot be enumerated.
Therefore, the paragraph enumerator is surrounded with an if-test to skip a paragraph if it’s really a table.
The paragraph enumerator returns text portions, represented by the TextPortion service.
TextPortion contains a lot of useful properties which describe the paragraph, but it doesn’t have its own interface (such as XTextPortion).
However, TextPortion inherits the TextRange service, so Lo.qi() can be used to obtain its XTextRange interface.
This hierarchy is shown in Fig. 35.
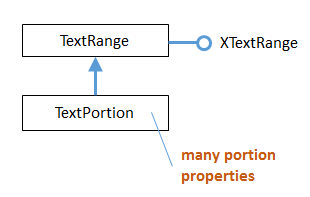
Fig. 35 :The TextPortion Service Hierarchy.
TextPortion includes a TextPortionType property which identifies the type of the portion.
Other properties access different kinds of portion data, such as a text field or footnote.
For instance, the following prints the text portion type and the string inside the txt_range text portion (txt_range comes from the previous code fragment):
print(f' {Props.get_property(txt_range, "TextPortionType")} = "{txt_range.getString()}"')
These code fragments are combined together in the Show Book example.
More details on enumerators and text portions are given in the Developers Guide at https://wiki.openoffice.org/wiki/Documentation/DevGuide/Text/Iterating_over_Text
5.9 Appending Documents Together
If you need to write a large multi-part document (e.g. a thesis with chapters, appendices, contents page, and an index) then you should utilize a master document, which acts as a repository of links to documents representing the component parts. You can find out about master documents in Chapter 13 of the Writers Guide, at https://wiki.documentfoundation.org/Documentation/Publications.
However, the complexity of master documents isn’t always needed.
Often the aim is simply to append one document to the end of another.
In that case, the XDocumentInsertable interface, and its insertDocumentFromURL() method is more suitable.
Docs Append example uses XDocumentInsertable.insertDocumentFromURL().
A list of filenames is read from the command line; the first file is opened, and the other files appended to it by append_text_files():
# part of Docs Append example
def append_text_files(doc: XTextDocument, *args: str) -> None:
cursor = Write.get_cursor(doc)
for arg in args:
try:
cursor.gotoEnd(False)
print(f"Appending {arg}")
inserter = Lo.qi(XDocumentInsertable, cursor)
if inserter is None:
print("Document inserter could not be created")
else:
inserter.insertDocumentFromURL(FileIO.fnm_to_url(arg), ())
except Exception as e:
print(f"Could not append {arg} : {e}")
A XDocumentInsertable instance is obtained by converting the text cursor with Lo.qi().
XDocumentInsertable.insertDocumentFromURL() requires two arguments – the URL of the file that’s being appended, and an empty property value array.